Today we’re introducing three new features that allow you to work with data at any scale: Query mode, Chained SQL, and Python pushdown.
As a bonus, we’re also removing the 5,000 row limit for Chart cells 🎉.
∞ Query mode
Query mode for SQL cells lets you work with effectively infinitely-sized data – no more worrying about memory overhead or limits.
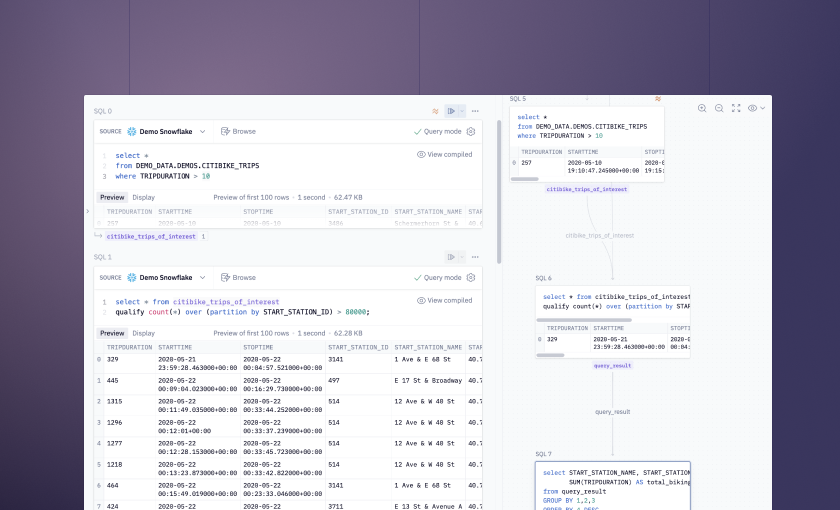
In Query mode, Hex leaves the data in the warehouse instead of bringing it into the in-memory kernel. It’s not just a limit preview though: like all cells in Hex, Query mode cells still return an object (in this case, a Query, in lovely purple) that can be used downstream and is represented in the DAG, but is just a pointer to the full result set.
When it’s time to build visualizations, or run in-memory operations over the full dataset, just move the SQL cell back into Dataframe mode (which is still the default). Read more in the docs.
⛓ Chained SQL
Chained SQL lets you reference previous queries with other SQL cells, relying on Hex to automatically combine the queries into common table expressions (CTEs) on the fly.
To use this, just reference any SQL cell result (a Query or Dataframe) in a downstream query using the same data connection. In the background, Hex will build the with...as statements for you, and you can see the fully-compiled query right there in the cell:
These “Chained SQL” queries work great with Query mode, allowing you to do multiple-step operations without pulling each intermediate result into memory. Then, at the end, you can flip the last cell into Dataframe mode and have a result set ready to use.
Chained SQL is complementary to Dataframe SQL, which lets you query any dataframe, including other query results, Pandas dfs, or even CSVs. Read more about when to use which feature in the docs.
💪 Scalable charts
Chart cells now perform server-side aggregation to let you plot data at effectively infinite scale. You can pass a dataframe of any size into a chart cell and aggregate it for display right from the chart configuration, without worrying about row or data limits.
Here’s an example of building a simple chart on a 900k row dataframe:
Under the hood, we're using VegaFusion to power this!
Other improvements
- We’ve made lots of upgrades to the Map cell
- We fixed an interesting issue that caused Chart cells to error when a dataframe had duplicate column names
- App editors now have the option to “Refresh cached state” on published apps, so you can manually reset the cache on an app.
- The default pandas installation has been updated to 1.4.2