We’re always working to make Hex better — and that includes investing tender loving care into core workflows like building viz, caching, and publishing apps. This week’s updates are focused on quality-of-life improvements that make it easier to customize charts, get fresh results, and understand performance.
⏱️ New app run and caching UX
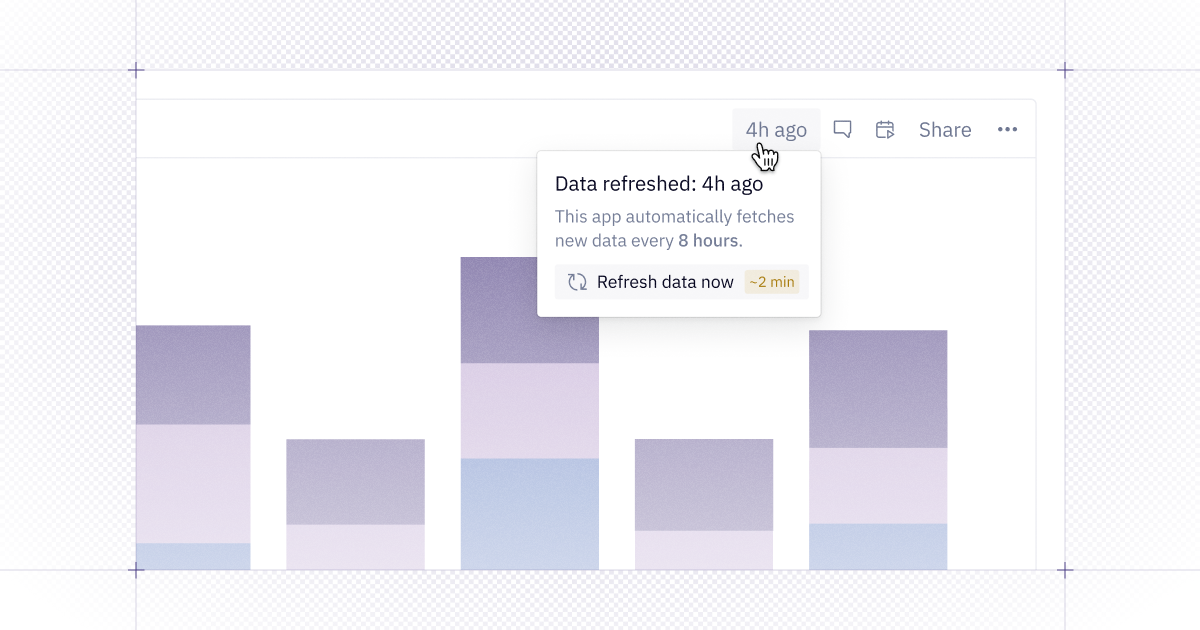
Our new and improved app run settings are now part of the publishing workflow and make it easy to keep apps up to date.
Most of the time, you want apps to reflect the latest data — and now they will. For new projects, the default is to auto-refresh published results: when someone clicks the refresh button, it updates the results for everyone, not just the person who ran it.
Additionally, if results are stale when you open a published app, Hex will kick off a refresh in the background. This means less time waiting for old results to re-run!
For existing apps, Editors can turn on auto-refresh or update results for everyone right from the published app. If you prefer a fixed snapshot instead, you can always restore a previous run from the run log and turn off auto-refresh behavior.
Other improvements include:
- A simpler, clearer app run settings menu
- More consistent display of data age on published apps
- Better handling for errored background runs
- New estimated run time information
Want to dig in? Read the full rundown in our docs.
📊 Chart cell upgrade
You may have noticed that chart cells recently got an upgrade! All newly-created chart cells come with an updated UI and new capabilities.
Behind the scenes, we've converged our chart cells with Explore, so the experiences are unified across both interfaces. You can now access powerful features in chart cells that were previously exclusive to Explore, including:
- Semantic models support: Chart cells now accept semantic models as a source, allowing you to build visualizations using governed dimensions, measures, and joins — right in your notebook.
- Spreadsheet-style calculations: Define dimensions and aggregate measures directly in chart cells. Aggregative measures (e.g., weighted average, ratio of sums, or any custom aggregation) are computed dynamically based on how your chart data is grouped.
- Top N: It’s now possible to specify the top (or bottom!) n values for a base-axis, color, or facet directly in a chart cell, cutting down the number of steps required to produce these types of visualizations.
- Custom start-of-week settings: Choose Sunday or Monday as the start of the week for charts and pivots. No upstream data wrangling required!
- New and improved config panel: We cleaned up the UI and added clickable pills to change aggregate types and date truncations.
- Drag and drop fields: You can now drag and drop fields into the config panel, or directly into the visualization empty state.
- Responsive layout: The config and data sidebars now auto-collapse based on screen width, so you can keep the Notebook Agent open without crowding the chart editing experience.
- And more here on drilling, viewing underlying data, and filtering on aggregates and measures!
Chart cells created before this update will continue to run, but won’t include the new features listed above. To upgrade, just hover over the “Legacy” tag in the top right corner of an existing chart cell and click “Upgrade.”
🏃 Improved run stats
We’ve made it easier to understand and troubleshoot performance with better run stats. You can now access reliable information about completed runs in your current session (from the last 48 hours) from the Help menu in the notebook view, or from the Debug View of an app run.
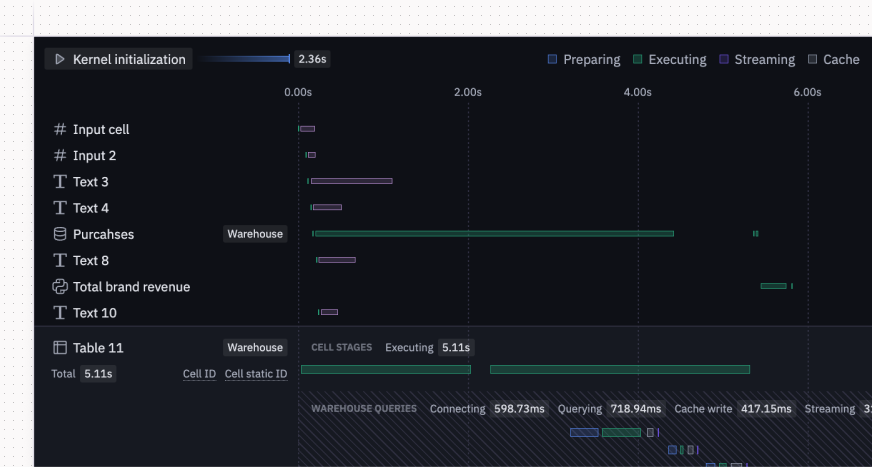
For cells that send queries to the warehouse (e.g., SQL cells and chart or pivot cells using query mode objects), we now show additional details including:
- Whether the query hit the cache
- Time spent querying vs. streaming data
- How much data was streamed
Other improvements
- Hex Agent in Slack for multi-tenant EU stacks: All multi-tenant customers (including those in the EU) can now install the Hex app in Slack, mention @Hex in any channel, and get answers directly in-thread.
- Stop scheduled runs: It’s now possible to kill actively running scheduled runs from a project’s run log!
- Smarter cell awareness for Notebook Agent: The agent now has context on which cells are published in your app, so you can say things like “review all cells in published app.” The agent also knows which cells you’re focused on or have selected. So when you ask, "Can you move the chart you just created under this cell?" it knows exactly what you mean — no @ mentions needed.
- Notebook Agent in Add Cell Bar & Shortcuts: It’s easier than ever to access the agent when you need it, right from the Add Cell Bar. You can also use keyboard shortcuts: Cmd+G for accessing the agent from the cell bar and Cmd+I for opening the agent sidebar.
- Customize Top N rankings: Instead of being limited to the existing aggregate or measure plotted in your visualization, you can now rank top N by any aggregate or measure.
- New GPU compute profiles: For compute-intensive workflows, we now offer A10G and L4 GPUs — bringing newer architectures, more GPU memory, and better cost-effectiveness than V100s.
- Delete Threads: Clean up your workspace with the option to trash threads from the homepage (via the three-dot menu) or in bulk from the Threads tab. They’ll be permanently deleted after 30 days.
- Clear all chart configs: Sometimes, starting over is the move. Look for the circular arrow icon in the chart config panel to clear all fields and formatting in one go.
- Click to fix “too many data points”: The “too many data points” warning now offers actionable solutions: click buttons to change the time grain, apply an aggregation, or use top N to reduce the number of data points plotted.
- Bug fix for chart loading state: Charts used to show an error icon next to columns while in a loading state. This has been fixed.
- Better query mode performance: SQL cells that return in query mode now run in parallel, leading to faster overall run time.
- @ mention dataframes improvement: You can now @ mention dataframes in the Notebook Agent even if they’re not in kernel memory. This is handy when you revisit a project and haven’t rerun all the cells!