One of the best parts of this job is seeing all the amazing, creative, beautiful things people build and share in Hex. You all put a ton of energy and love into your work – and you want it to look great!
So today, we’re rolling out a couple of big improvements to your apps that’ll help you make them snazzier than ever. You can add tabs to better organize complex projects, and our drag-and-drop layout engine has a bunch of improvements to make it even easier to make pixel-perfect reports.
We’ve also made massive improvements to SQL typeahead and schema search speed. It feels great, and you’ll notice the difference right away.
🗂️ Organize apps with tabs
Hex is great for building complex projects with lots of inputs and outputs – but when it comes time to share, the single scrolling container isn’t always the best way to lay things out.
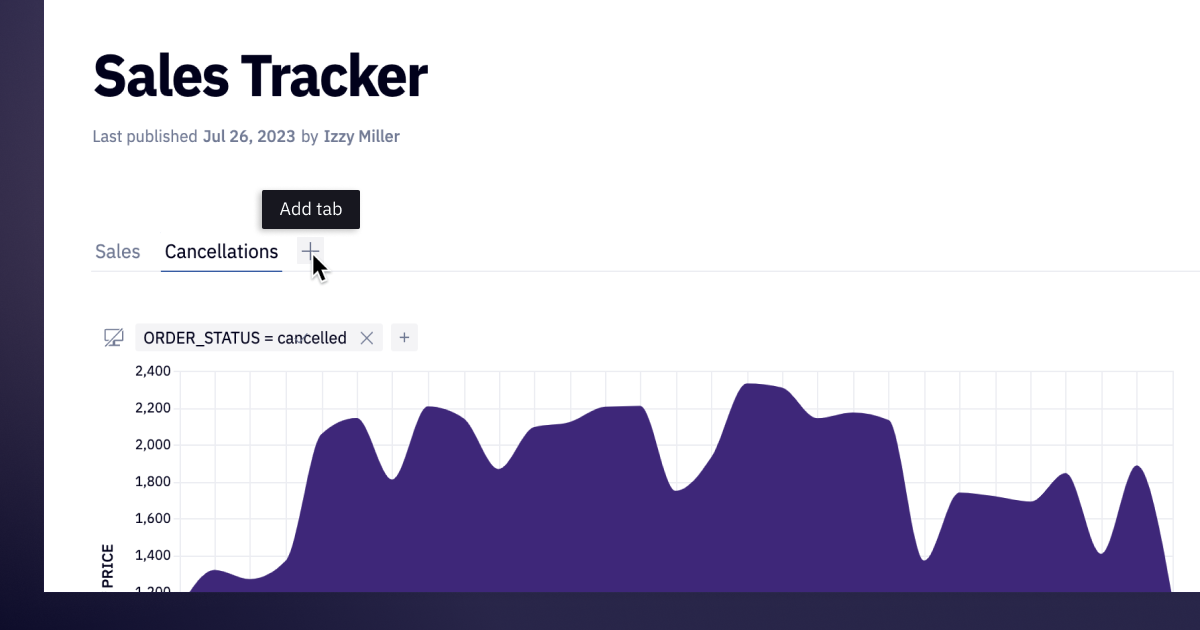
Now, you can use Tabs to organize your outputs into, uh... tabbed pages… or “tabs”, for short, to help folks navigate your more complex apps.
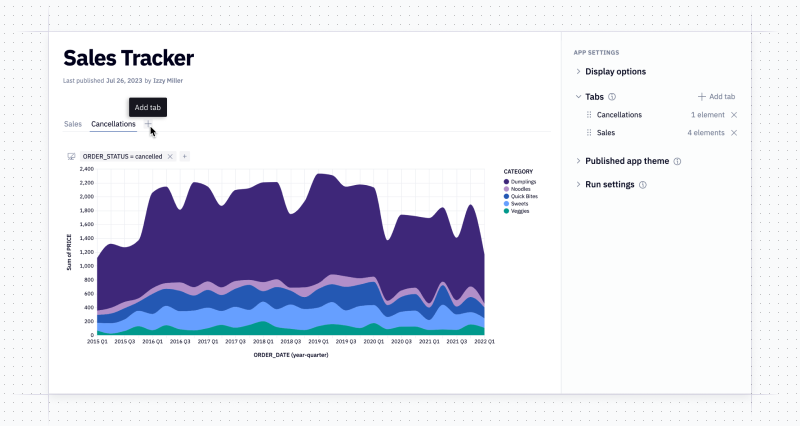
You can add, re-order, and name tabs from the top of the editor, or via the redesigned App sidebar on the right.
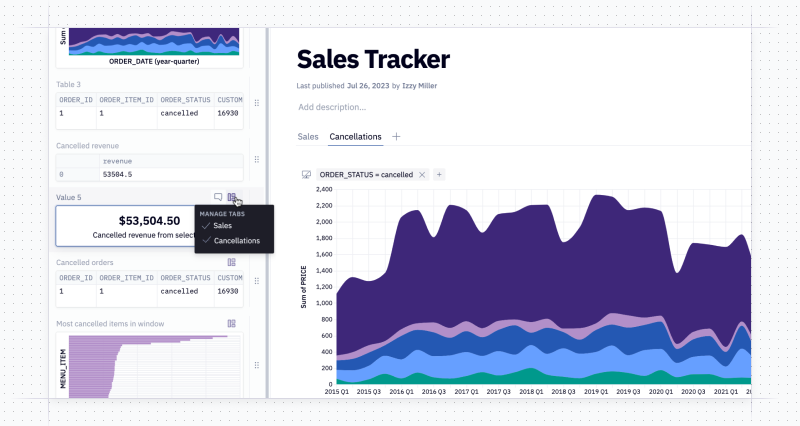
It’s easy to drag-and-drop cells across tabs, and you can even add cells to multiple tabs. For example, if you have a filter that affects a bunch of downstream charts, you can add it to multiple tabs and it’ll be synced automatically, just as you’d expect.
🎨 More layout improvements
We’re also upgrading the core report building experience!
We updated the layout engine powering all your apps to make it easier to create pixel-perfect layouts, including adding new guides for re-sizing and drag affordances.
Finally, all settings relevant to your published app have been consolidated into a single sidebar. you can adjust settings for runs, layouts, and – yes – tabs.
Here’s a one minute clip from Melissa, the engineer who worked on this, showing off the improvements!
🚅 SQL autocomplete speed
If you’ve noticed snappier autocomplete and schema search lately, no, you didn’t just get lucky. Over the past few weeks we’ve been rolling out an architecture change that makes this MUCH faster.
We’ll let the data tell the story (can you tell what day we cut over?!):
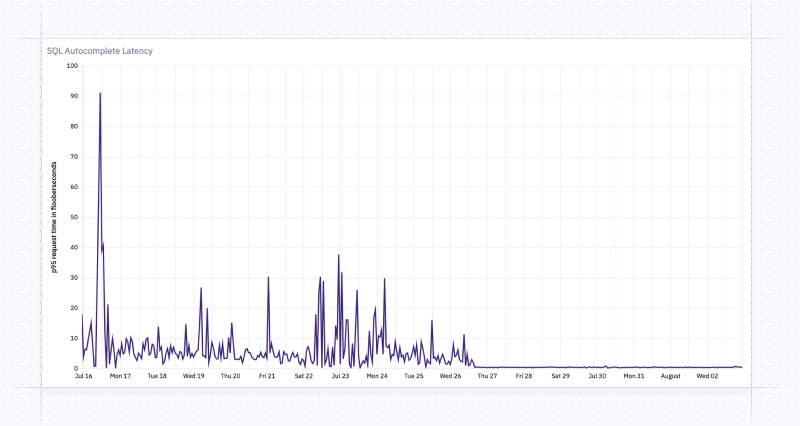
The larger your database, the more likely you’ll be to notice this speedup – our data team certainly has!
This applies to both in-cell SQL autocomplete, and the schema search in the side bar. Oh, and now autocomplete matches any part of the object, so you can just type name and get first_name as a suggestion.
Editors note: Once upon a time I attempted to make this change myself, but literally gave myself a migraine trying to understand the codebase and had to go to bed early, without any supper. Will stick to marketing 👍.
We’re also progressively rolling out changes to make schema browser refreshes actual orders of magnitude faster — if this hasn’t hit your workspace yet, you can expect it in the next week or so. You'll know when it lands for you because you'll see one initial refresh that will actually take longer than usual, and then subsequent ones will be lightning quick.
I hope that this all helps you feel… complete. I certainly do.
Other improvements
-
We fixed an issue that caused private slack channels to not show up as scheduled run destinations.
-
We fixed some errors that were appearing when chart cells were ejected to Python. Custom SQL formatting was temporarily disabled while a security patch was applied to the open source library we use. It’s now re-enabled!
-
We pulled some strings, called in some favors, and now dataframes printed with a custom df.style() can display emoji 🤪 .