Project execution & performance overview
What impacts how a Hex project/app runs? There are a few different places under the hood of your Hex project that need work in harmony for a project to run effectively!
Kernels
Each Hex project is powered by its own kernel, an individual program that bridges the gap between the logic you’re creating and the cloud infrastructure that executes it. Every Hex project gets its own kernel, so you don’t have to worry about different users in different projects competing for resources. Every time a user lands on a published app, they get their own kernel specifically for that app session. This again mitigates resource contention, and ensures that users can interact with an app on their own without changing the app for others viewing it at the same time.
Read more about how kernels work and how you can control them here. You can change the compute for your kernel, bumping up its virtual CPU and RAM so that it has more power and memory to carry out complex tasks
Graph Execution
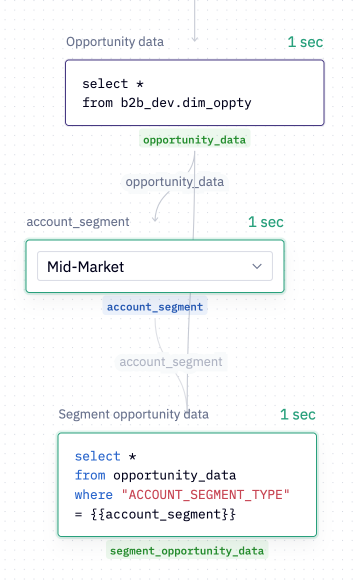
As you add cells to your project, Hex automatically infers the relationships between them and constructs a graph behind the scenes. This graph helps Hex understand the most efficient order of operations for project execution, meaning it can decide when to:
- Run all of a cell’s dependencies to ensure that cell has up-to-date data and inputs flowing into it
- Reorder when cells are run to optimize for efficiency
- Run cells in parallel when they’re not dependent on each other
- Skip cells that aren’t needed to render a published app
Read more about Hex’s execution model!
Caching
When you query data from an external warehouse to bring into Hex, that result set can be cached. When downstream queries reference that result set, those queries will run against the cache instead of against the external warehouse. This speeds up runtimes, mitigates the risk of concurrent queries causing resource contention in the external warehouse, and reduces compute consumption in the external warehouse. This is applicable to both results stored in dataframe and query mode objects. Your Hex Admins enable caching and a default cache timer at the workspace level. This default is inherited by your projects; however, you can adjust this at the project level in a few ways:
- From the Environment tab of the left sidebar, you can turn off caching for the project (not recommended).
- From the Environment tab of the left sidebar, you can change the cache timer to either increase or decrease it.
- Within an individual Data Connection SQL cell, you can opt to rerun without cached results
- In the App run settings menu of the App Builder, you can set a cache timer for published apps.
- On a published app, you can opt to rerun the app without cached results from the three-dot menu.
OAuth data sources
If your data connections have OAuth enabled and token sharing disabled, caching works a bit differently than it for standard Hex data connections.
Let’s start with the big takeaway: SQL caching works in Hex with OAuth enabled!
Once a user follows the authentication workflow from Hex to their warehouse and gets an access token, Hex stores that token behind the scenes. Each time a query is run, Hex and the warehouse do a quick check to make sure that you are who you say you are, and that the data being returned reflects only what you have permissions to see in warehouse.
When a data connection that doesn't authenticate with OAuth is used, users can access cached SQL result sets from across the workspace, regardless of the user who initially ran the query. This means that if Editor A runs select * from superstore in Project 1 and Editor B runs the same query in Project 2, as long as the cache timer hasn’t expired for the query, the results will pull from the cache.
However, when OAuth is enabled on a data source, users aren’t able to use cached SQL from across the workspace. This is because Editor A’s SQL query was run in the warehouse with their own authorization token. Editor B will need to run the query with their authorization token to verify they can access the same data. This prevents a situation where Editor B sees data they don't have permissions to because Editor A has different privileges than they do.
With OAuth data connections, instead of thinking about caching across a workspace, think about caching on a user-level instead. Once Editor A runs that select * from superstore query, its results are cached for Editor A. If they run that query again, or they run a chained query downstream against it, it will hit their cached version. Each user needs to run a query once to create their own personal cached results.
App Execution: Order of Operations
Loading an App the First Time
When you open a published app for the first time, a few things happen:
- Hex activates the app kernel -- The kernel for the app session is acquired and activated.
- Hex checks to see if the app is set to pull from cached queries -- If it is, it checks to see if the logged in user has a cache available to them. If they don’t have an available cache or caching is turned off for the app, Hex sends the query out to the external warehouse.
- Hex runs all dependent cells in the project -- Since it just acquired a fresh kernel, nothing is in its memory yet. This means it needs to run all of the logic that's associated with the cell that a user has interacted with in order to generate the dataframes and variables that populate its cells.
Interacting with the App
Your hex app has loaded… but that’s not the end of it. Now, as app consumers interact with it by selecting values in input parameters or applying filters, the app needs to dynamically rerun and recompute based on those user’s selections. For this, Hex first checks to see if there’s an available cached result set to pull from.
Let’s say a user selects a value in an input parameter that’s referenced in a SQL cell. If you’ve constructed your logic to:
- Use chained dataframe SQL: Any downstream SQL cells will query against the cached result from the initial SQL cell that went out to your warehouse.
- Use chained data connection SQL: Any downstream SQL cells will construct a CTE referencing the initial SQL cell and send it out to the warehouse. If it’s returning in dataframe mode, this new result set is cached.
- Use chained query mode SQL: Any downstream SQL cells will query the warehouse, and the resulting query object is cached.
Now let’s say that the SQL cell that was updated by the input parameter generates a dataframe used in 3 out of 5 charts in the app:
- Those 3 chart cells will rerun and re-render
- The other 2 won’t since they’re not affected by any of the changes made by the user interaction
Performance Recommendations
Query Caching -- Keep query caching enabled for both your notebook and its published app! Whenever possible, extend the query cache timer so that the cached results can be referenced for longer.
Project Size
It might be tempting to build long Hex projects with hundreds of cells, but we recommend keeping your project to around 200 or fewer cells. This is a rough heuristic, since the details of your project strongly influence its performance (e.g. number of chart cells, size of data, complexity of logic). Projects larger than this can experience lag due to a few factors:
Cells require browser resources to render
More cells means more browser capacity is consumed, which can translate to sluggish performance while scrolling and navigating (read more about how Hex optimizes for browser performance with virtualization). In the Notebook, we recommend organizing your cells into sections and collapsing them. In apps, using tabs can help limit what the browser tries to load at one time.
Project run times grow larger with more cells
While Hex prunes select unused cells from the published app DAG, it does not eliminate everything. For example, Python cells are always executed. This means that if you have unused or unnecessary code in your project, it can still run in the background and increase the time needed for your published app to process. We recommend removing or commenting out any unused logic.
Input Parameters
Be thoughtful when passing input parameters into data connection SQL:
- Every time you change an input parameter referenced in a SQL query, it changes the query.
- In a Data Connection SQL cell, this reduces your ability to reference the cached results.
Example: Let’s say you have a dropdown input parameter with options A and B. You select option A,
which generates the query select * from table where field = A. Then you select option B, which
generates the query select * from table where field = B. Since each of these are different queries, they’ll each need to hit the warehouse before their dataframe result set is cached.
- Instead, pass the input parameter into a chained dataframe SQL. When the chained SQL cell runs, it will run against the cached results.
Example: You have SQL Cell 1 that sends the query select * from table to the warehouse and stores the results in a cached dataframe. You then have a dropdown input parameter with options A and B. Finally, you have SQL Cell 2 that generates the query select * from dataframe where field = {{input_parameter}}.
When you select option A, the query select * from dataframe where field = A is run against the cached dataframe instead of sent to the warehouse. Results will return faster since they do not need to traverse from the warehouse to Hex.
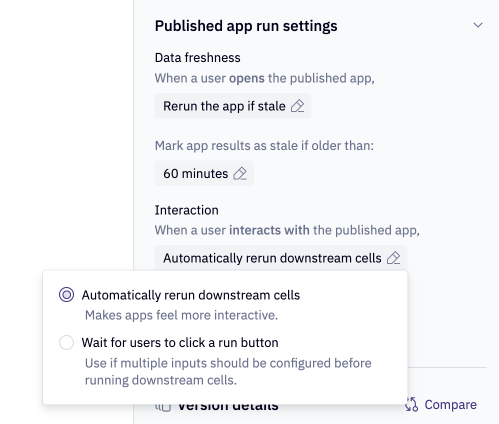
App Run Settings
If your app includes input parameters but does not have complex SQL logic sent to the warehouse or running on large data (> ~2M rows):
- Toggle on Auto-rerun cells in App run settings to automatically rerun downstream cells.
If your app includes a number of input parameters AND it includes complex SQL logic, large query results, or does not use chained dataframe SQL:
- Toggle off Auto-rerun cells in App run settings to wait for users to click a button.
- This will prevent Hex from automatically running computationally complex queries each time a user selects a value from an input parameter.