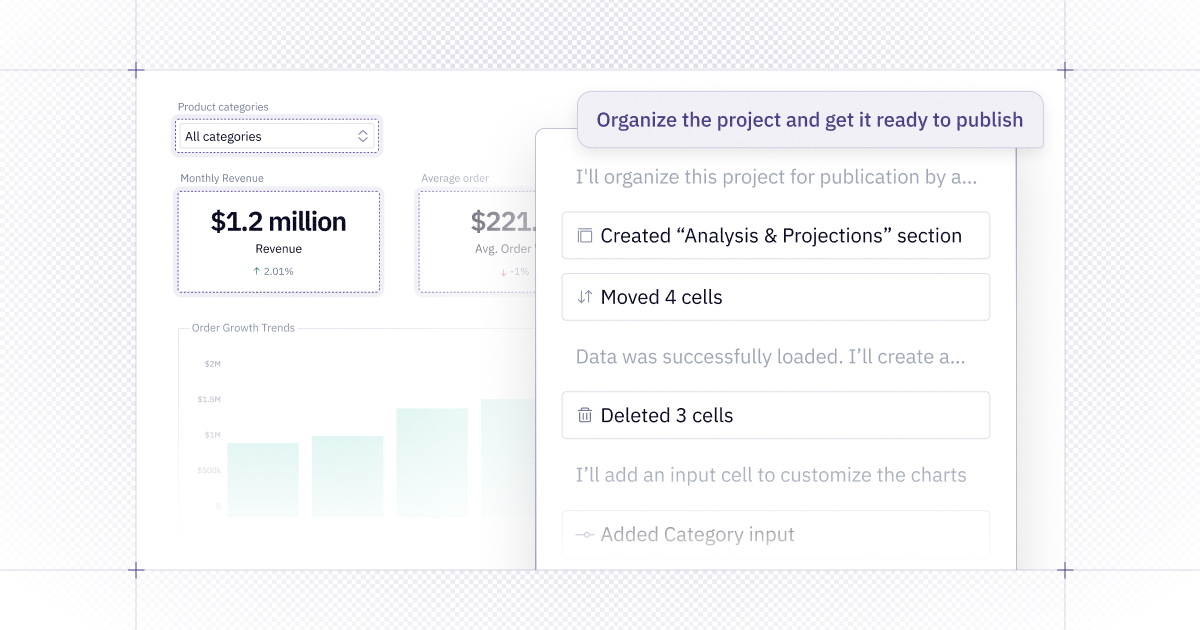
Data teams are playing a crucial role in governing the quality of AI responses, just like they did with trusted dashboards in the pre-AI era.
This week’s updates include tools for understanding agent behavior, a cleaner entry point into self-serve analysis on top of semantic models, and more improvements to Threads!
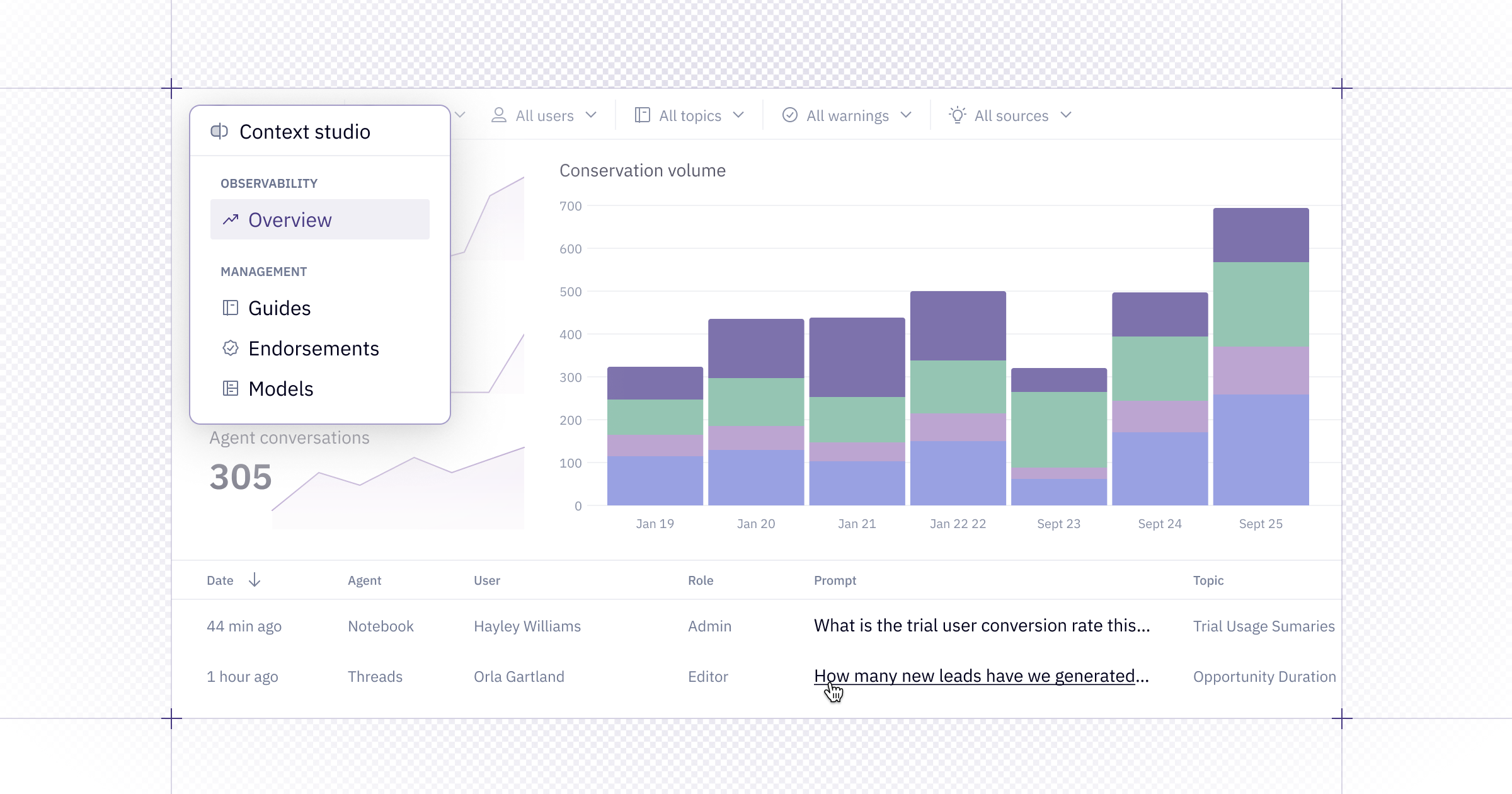
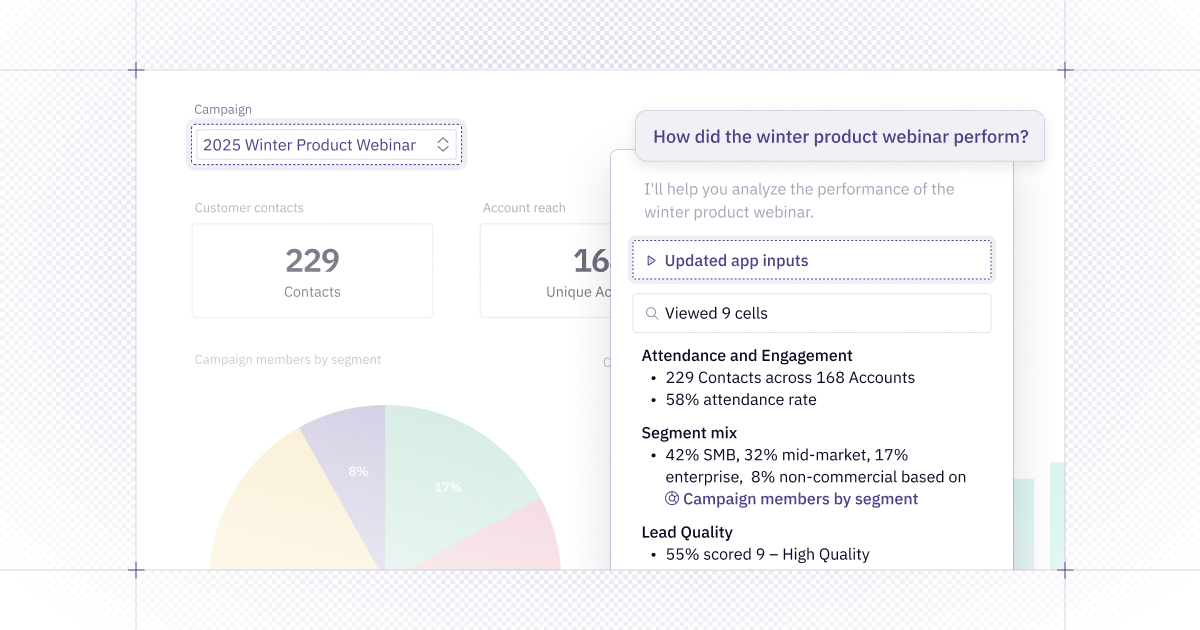
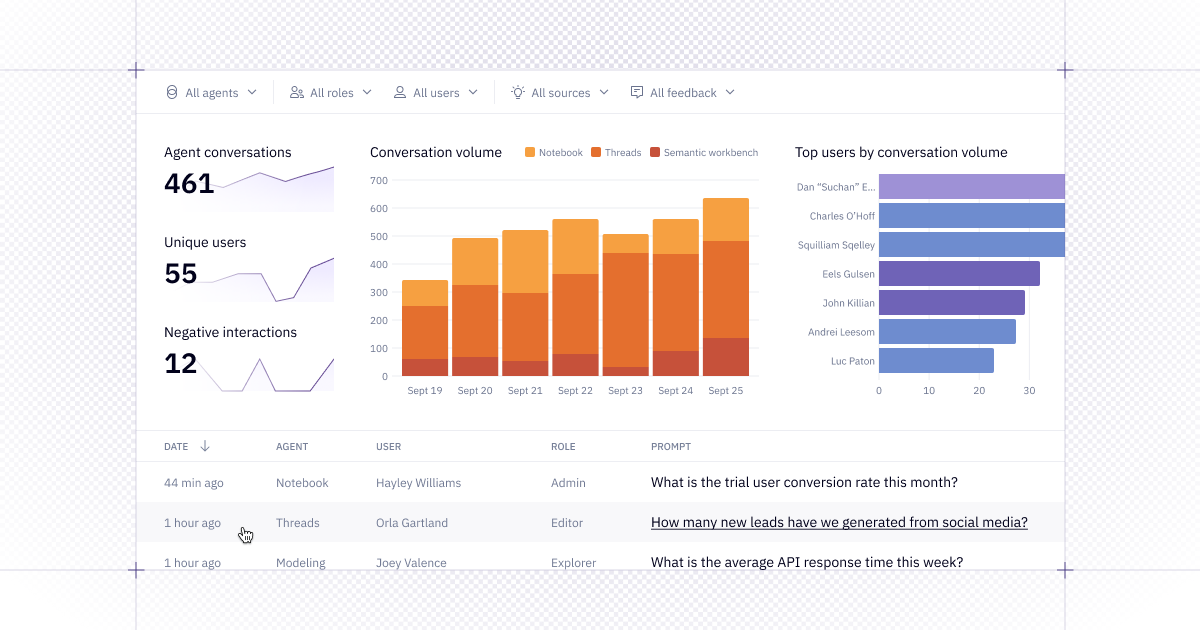
👀 Agent observability in the new Context Studio
We're bringing observability and context management together in the new Context Studio — giving you the tools to manage what data is trustworthy and how agents should use it.
On Team and Enterprise plans, Admins and Managers can open up the dashboard in the Context Studio to understand how agents are being used, what users are asking, and where performance excels or needs improvement.
With this view, you can:
- Track conversation volume
- Identify your most active users
- Spot patterns in user feedback
- Filter by agent type, workspace role, time range, and more
Admins can also dive into individual conversations to:
- Review the agent's reasoning
- See what context it referenced
- Diagnose where improvements are needed
Managers get access to aggregated metrics but not individual conversations.
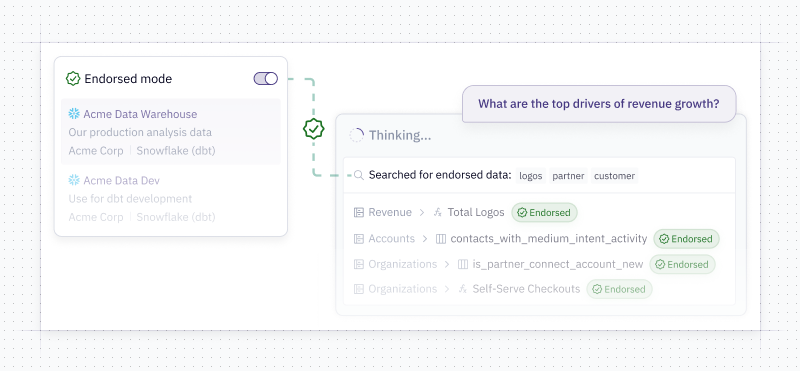
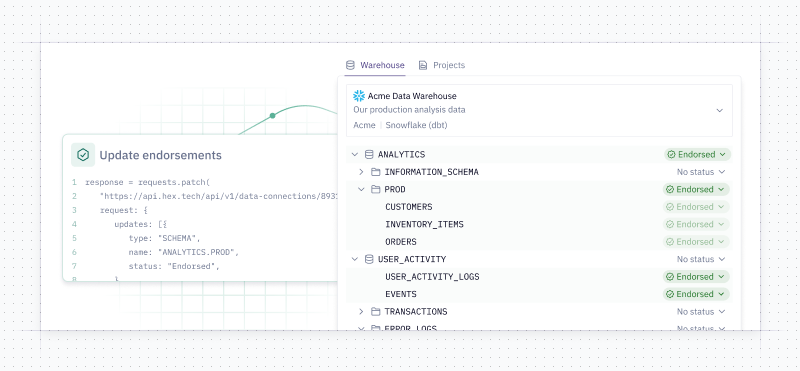
When you're ready to make adjustments to the agent’s behavior, you can hop over to the Context sources tab, where we’ve unified settings for workspace rules, data endorsements, and semantic projects in one place.
There is so, so, so much more coming soon here — so share your feedback and stay tuned.
🪟 Views on semantic models
We’ve introduced views as a new layer on top of semantic models, designed for clarity and readability.
As your data models grow, you can create views in the Modeling Workbench to rename and reorganize dimensions and measures — giving business users a cleaner, more intuitive starting point for self-serve analysis.
Views can help slim down wide tables, simplify complex join trees, or even flatten relations. Now you can scale the complexity of your underlying models, then surface only curated views that are easy for end users to explore and understand.
📁 CSV uploads to Threads
You can now upload CSVs to Threads, and the Hex Agent can craft queries against the data in the file provided. The agent is also capable of joining the CSV data with existing warehouse data, enabling cross-source insights from a simple file upload.
This is available to users with the Explorer role or higher who have permission to access non-semantic data in Threads. Admins can configure agent data access and data connection defaults in the Threads settings page.
🧵 More Threads improvements
We’ve made a bunch of additional improvements to Threads!
You can now copy and download charts, pivots, and tables in Threads. Want to add a chart from Threads to your presentation slides? Or import the data in a table into a spreadsheet? You can copy results to your clipboard, or download them as images or CSV files.
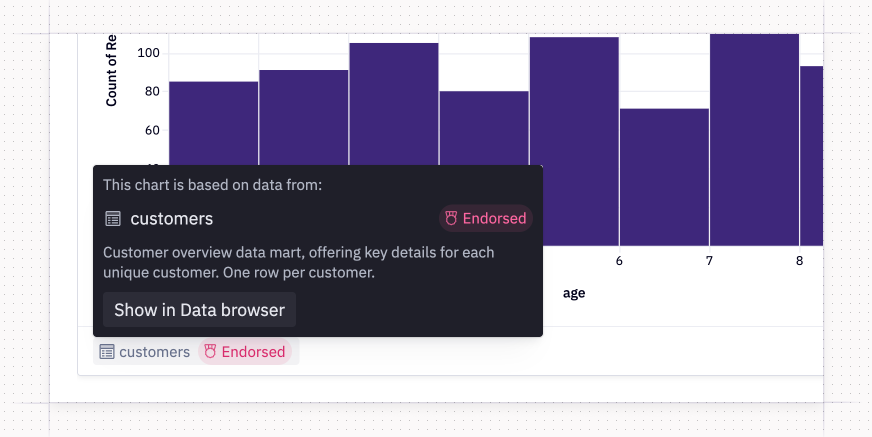
When a chart or pivot is built directly on a semantic model, we’ll tag the name of the model directly in the footer of the visualization. This provides a standardized way to check the data source at a glance.
We’ve also made Threads faster at answering simple quick questions. When you ask a question, the agent will gauge the complexity; if it’s deemed an “easy” question, the agent will spend less time thinking and return a quicker response.
Give these improvements a spin by trying our new Threads browser shortcuts! hex.new has always been the shortcut for creating a new project in Hex, and now you can enter threads.new in your browser’s address bar to create a new thread. For an even quicker shortcut, use threads.new?prompt= followed by your question.
📐 User-level agent instructions
If you want to steer the agent to behave in certain ways — whether it’s the SQL style or just the agent’s tone — you can now add user-level rules files to customize the styling and preferences of the agent’s responses.
From the custom instructions modal, you can also see the workspace context that Admins have added for your organization.
Other improvements
- Better bulk column editing experience: The Columns menu in the lower right corner of SQL and table cells got a UX refresh and new capabilities! You can now reorder, hide, and pin columns from one tab, and bulk format them in a separate tab.
- Chart upgrades by the Notebook Agent: If you use the Notebook Agent to modify a legacy chart cell, the agent will automatically upgrade the chart cell on your behalf in order to make the changes you ask for.
- Start Threads from workspace search: You can use the keyboard shortcut Cmd+K to open workspace search, type in your question, and start a thread from there.