Snowpark integration
As of October 2025, some features of the Snowpark integration have been deprecated. Learn more below.
Hex lets Snowflake users take advantage of Snowpark, from their Hex projects via Python. Unlike with standard Pandas dataframes, these are not loaded into the memory of a Hex project. Operations on Snowpark dataframes are executed on Snowflake’s infrastructure. This enables Hex users to operate on large datasets without requiring additional memory in Hex.
To learn more about Snowpark, visit the Snowpark Developer Guide.
Enable Snowpark
Snowpark can be enabled on both workspace and project-level Data connections. To enable Snowpark on a Workspace Data connection, a Hex Admin will need to update the connection via the Data sources page of the Admin settings. To enable Snowpark in a project data connection, navigate to the Data sources tab in the left sidebar of the project, locate the data connection for which you'd like to enable Snowpark, and select Edit from its 3-dot menu.
In the Snowflake Data connection's settings, scroll to the Integrations section, and toggle on Snowpark.

Use Snowpark in a Hex project
Using Snowpark dataframes can be an effective way to manage memory usage in your Hex project. Operations on Snowpark dataframes are executed within your Snowflake infrastructure, and Hex won't pull the contents of your dataframes into memory unless you choose to do so. Under the hood, this is possible because Snowpark writes your dataframes to a Snowflake temp table directly in your warehouse.
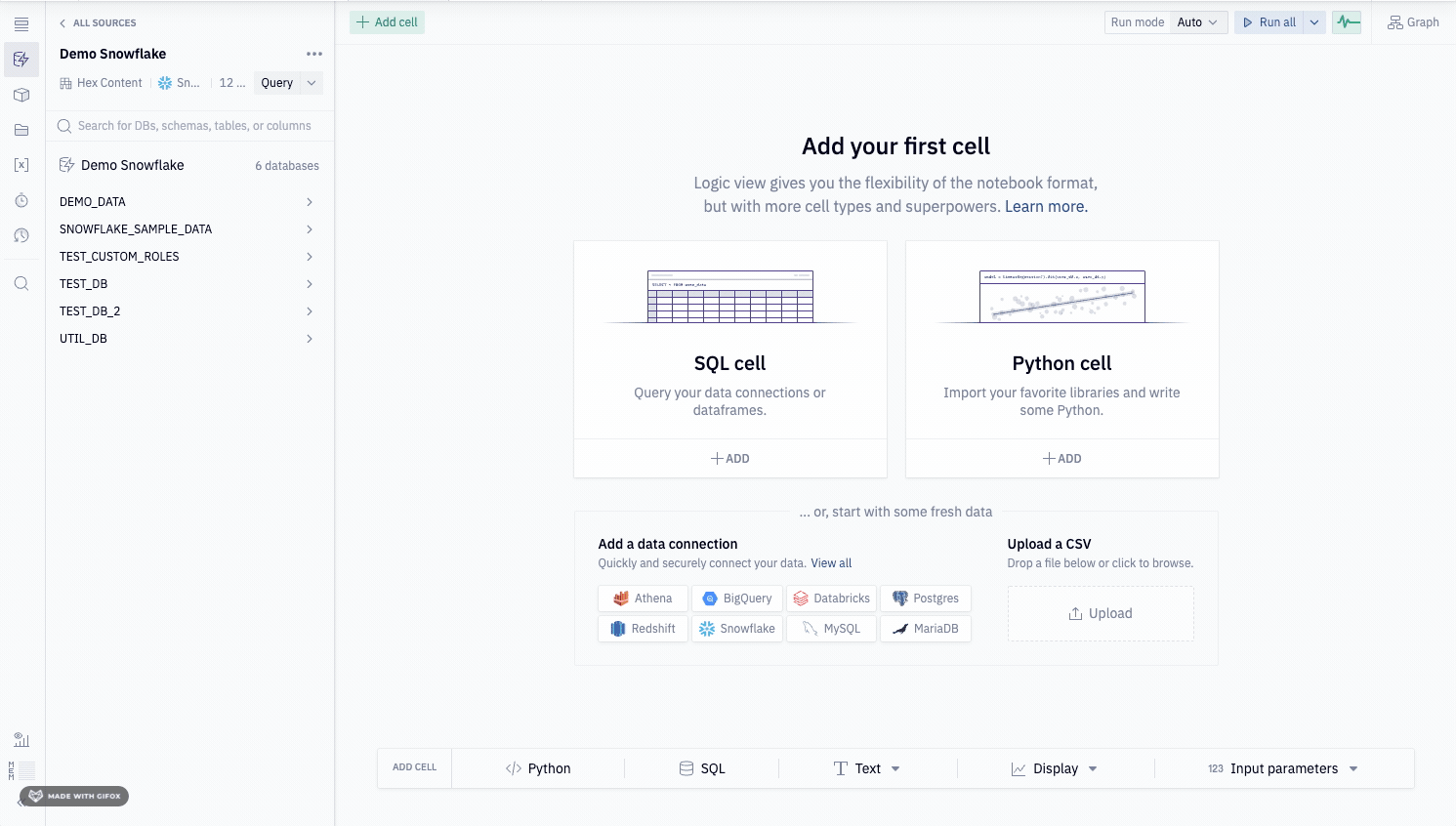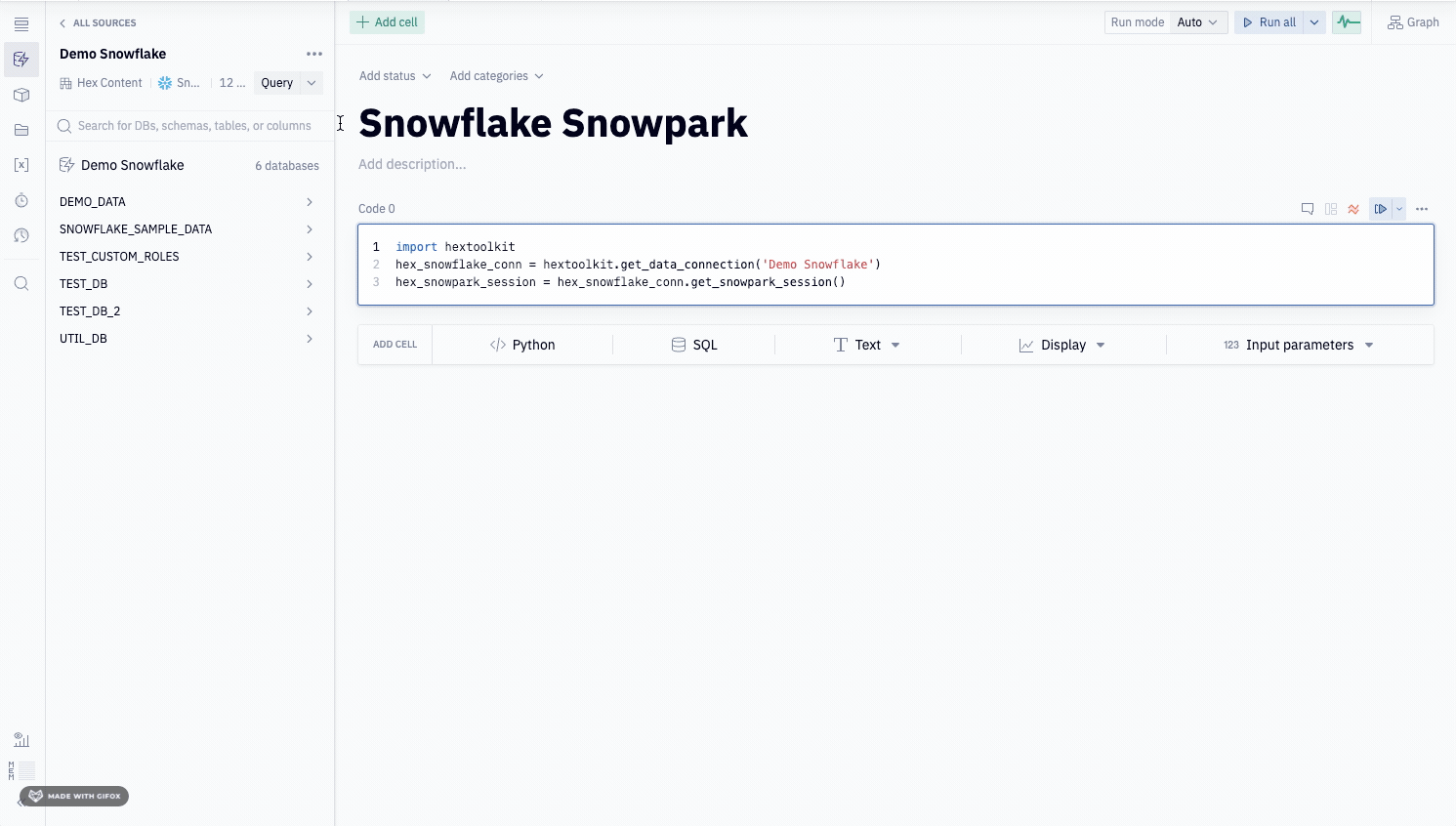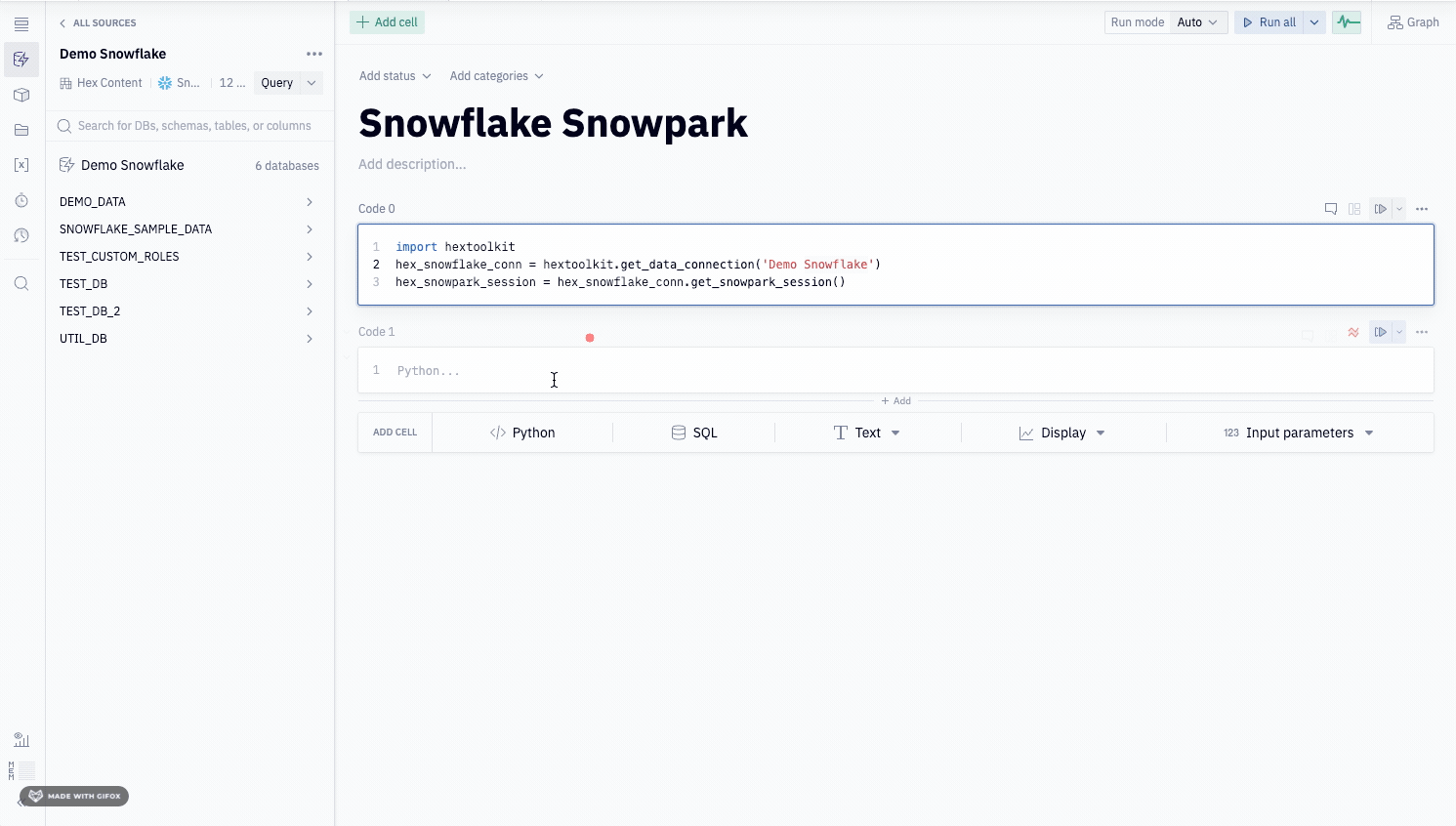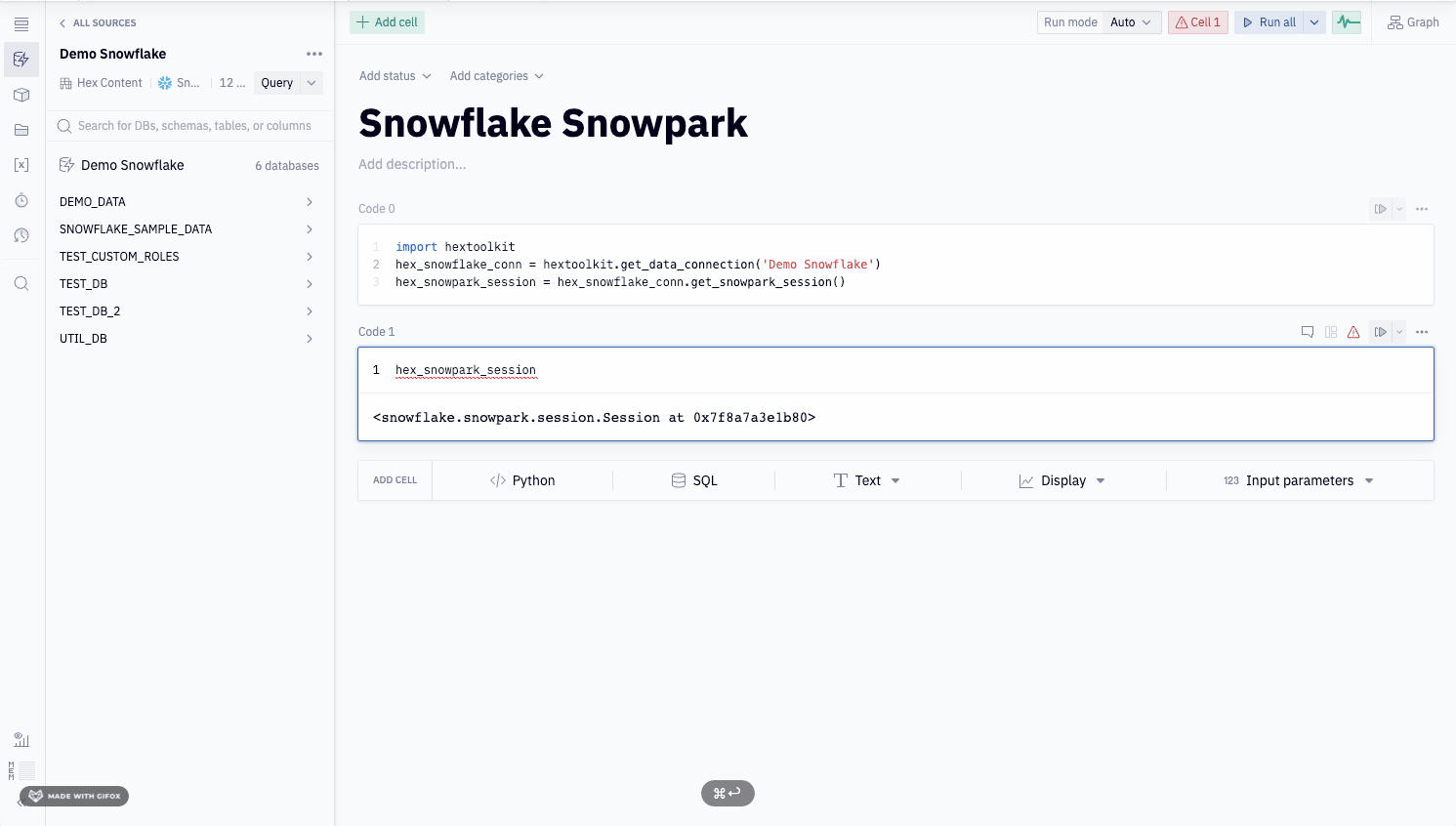
To use Snowpark in a project, first import the connection that has Snowpark enabled into your project. Once imported, Hex will create a Snowpark session on kernel startup, and automatically closes that session when a kernel shuts down.
To access this Snowpark session from a Python cell, create a cell with the following code replacing the argument of the get_data_connection method with the name of your connection.
import hextoolkit
hex_snowflake_conn = hextoolkit.get_data_connection('My data connection')
hex_snowpark_session = hex_snowflake_conn.get_snowpark_session()
You can also generate a Python cell with this code from the Data browser menu:
Then, use Python to create Snowpark dataframes. Use the Snowpark library to perform additional transformations.
df = session.sql("select 1/2")
To use the Snowpark dataframe as the input to a chart, pivot or other cell, you'll need to convert it to a Pandas dataframe using the .to_pandas() method.
By default, Hex will attempt to parallelize the execution of code when possible. Manually closing your session with session.close() may cause this parallelization to end your session prematurely.
If you manually close the default Snowpark session initiated on kernel startup, you will need to restart your kernel to restore your session or manually create a new session via the Snowpark API.
Deprecated features
As of October 2025, some features of the Snowpark integration have been deprecated, in order to reduce system complexity, and simplify how projects can be run. The following features have been deprecated:
- Returning a Snowpark dataframe from a SQL cell: If you were relying on this feature, you can either:
- Use query mode to work with large datasets
- Create a Snowpark dataframe with Python if you intend to operate on this object via Python. You'll need to convert the final Snowpark dataframe to a Pandas dataframe to use it in a chart cell, with the
to_pandas()method.
- Using a Snowpark dataframe as the input to a chart, filter, pivot, or single-value cell: If you were relying on this feature, you’ll need to convert your Snowpark dataframe to a Pandas dataframe before using it as the input for a cell.